
使用burp和yakit在互联网抓取get和post数据包
burp
首先打开burp,然后在自己的浏览器(例如Firefox)打开随机页面。最后返回burp,点击Proxy下的HTTP history选项查看历史报文信息。
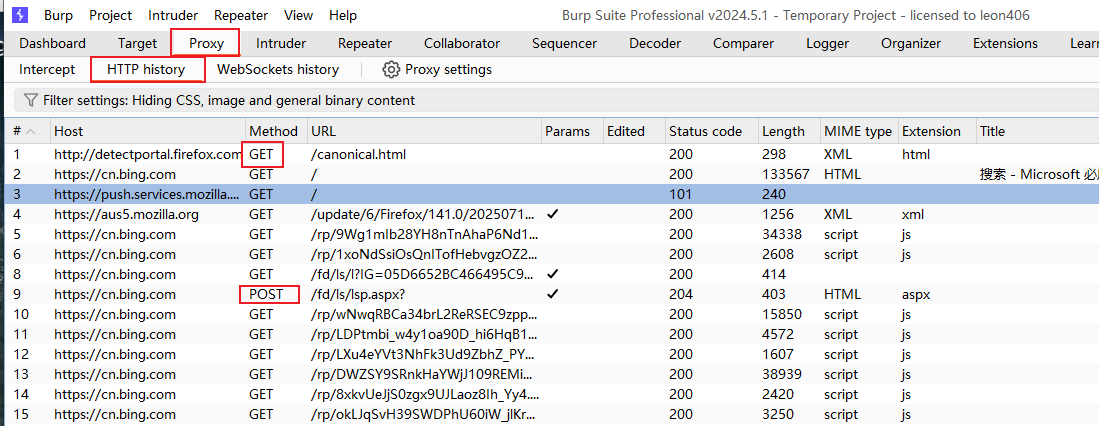
GET包
随便点击一个上面的历史包查看信息
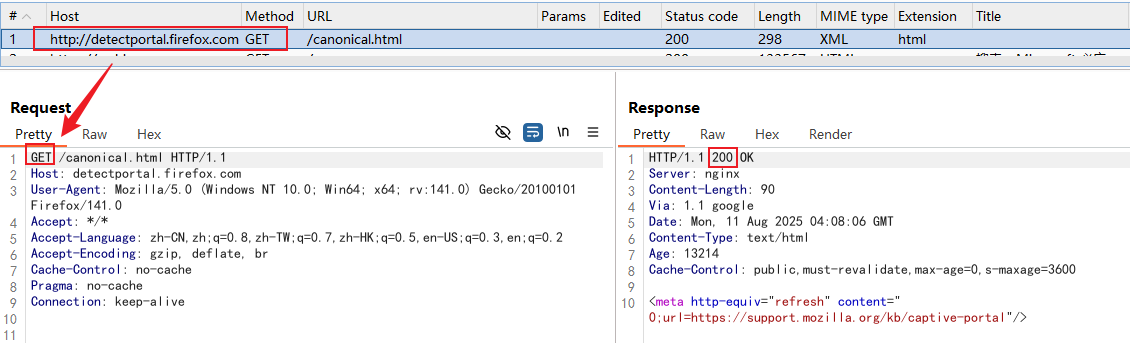
POST包
yakit
GET包
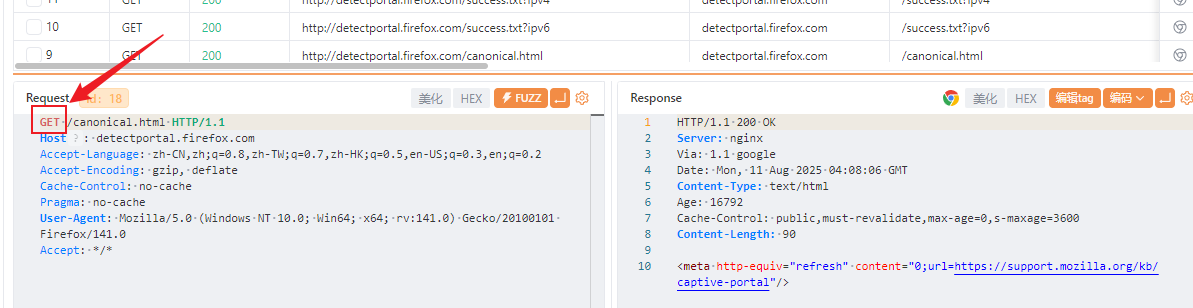
POST包
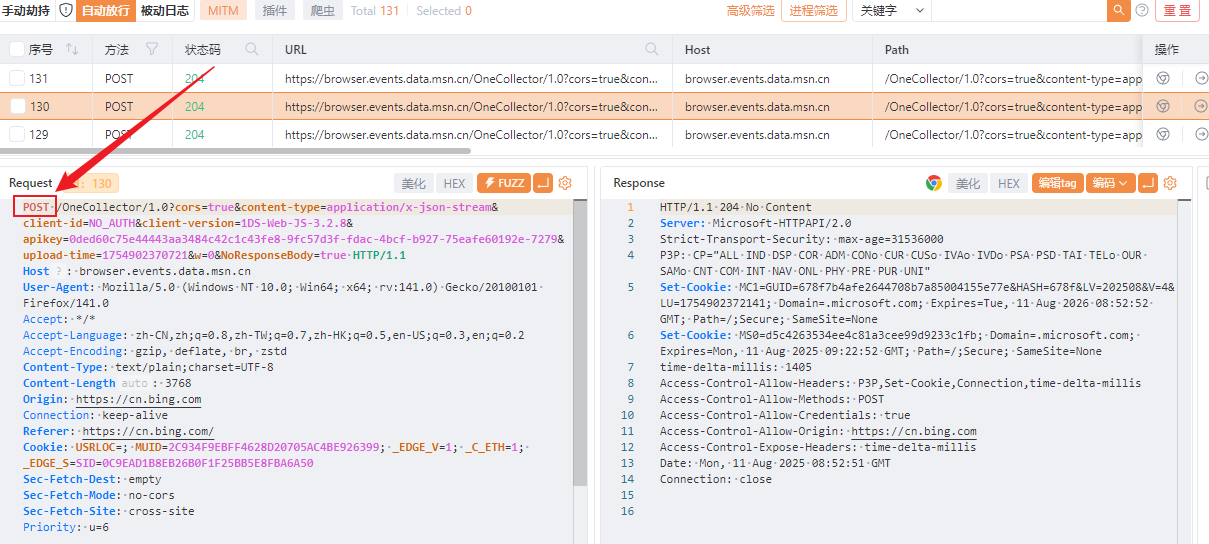
截图描述请求报文和响应报文字段的含义,以及这个字段在渗透测试中可能有什么作用
以这个get包为例
左侧的请求报文
| 字段 | 含义 | 渗透测试作用 |
|---|---|---|
| GET | http的请求方法 | |
| Host | 目标服务器域名 | 虚拟主机探测、域名劫持 |
| User-Agent | 客户端标识 | 注入恶意载荷,绕过WAF |
| Accept | 客户端支持的响应内容类型 | 修改为*/*探测服务器响应差异 |
| cookie | 客户端身份信息 | 窃取会话ID,修改权限参数 |
| Referer | 上一个请求地址 | 伪造来源,窃取URL敏感参数 |
右侧的响应报文
| 字段 | 含义 | 渗透测试作用 |
|---|---|---|
| 200 | 状态码,标识响应信息 | 判断服务器信息(403;目录/文件枚举) |
| Server | 服务器软件信息 | 识别服务器版本,寻找版本漏洞 |
| Content-Length | 响应Body的字节长度 | |
| Content-Type | 响应Body的类型 | 强制类型转换,探测MIME嗅探漏洞 |
| Cache-Control | 控制缓存行为 | |
| Set-Cookie | 服务器设置Cookie | 检查HttpOnly/Secure缺失,测试Cookie劫持 |
安装phpstudy访问web页面,尝试触发404操作
打开虚拟机中的Apache和Mysql
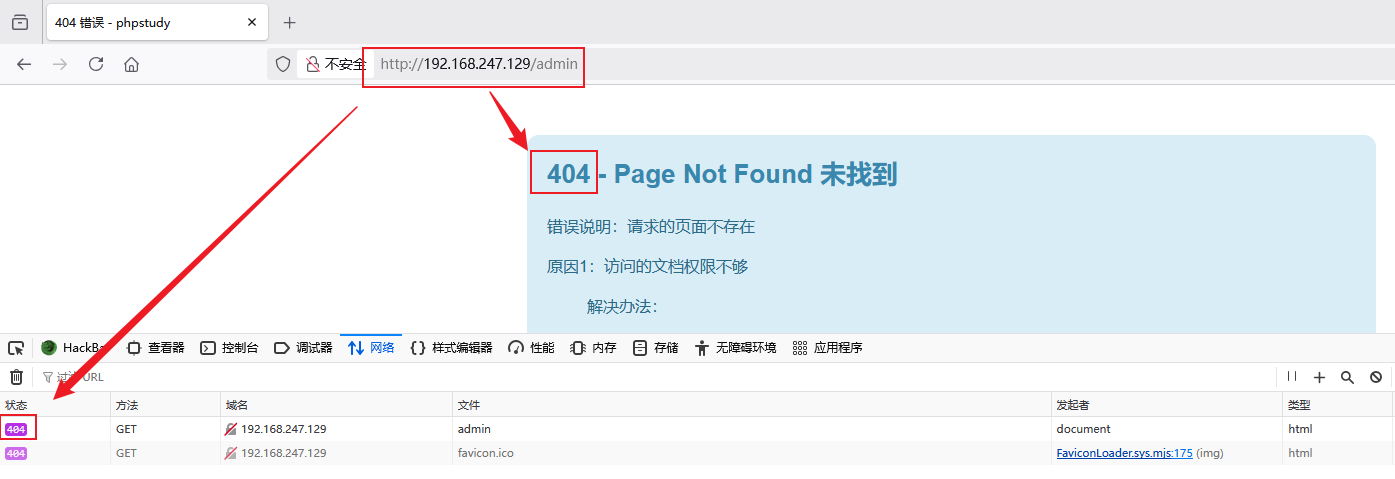
在自己主机上访问虚拟机创建的网站,后面加上/admin一个不存在的路径,触发404 Not Found
尝试修改yakit,burp默认的监听端口号,再进行抓包
浏览器
打开浏览器(例如Firefox),配置网络设置
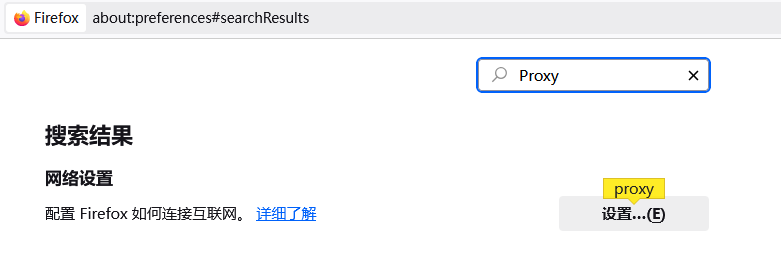
修改代理端口和后续burp或yakit的端口一致
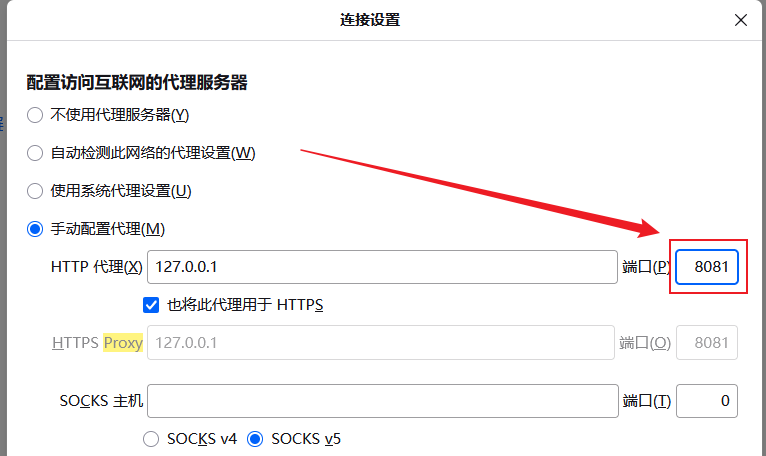
burp
打开burp的Proxy,选择Proxy settings选项,点击需要修改的项选择Edit,修改端口即可,这里改为8081
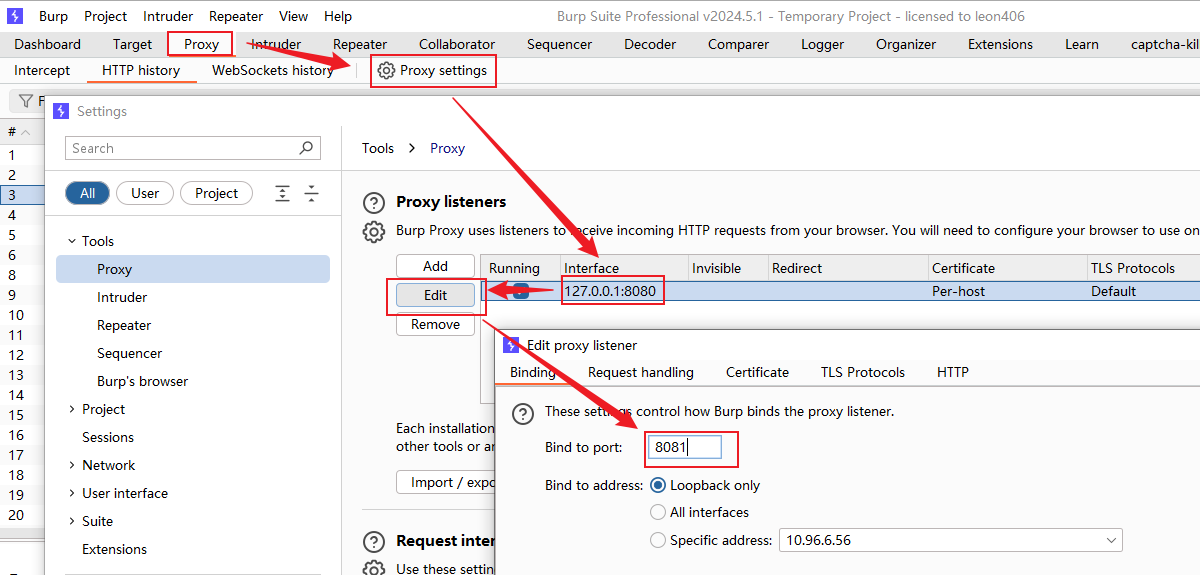
burp抓包,右侧端口变成8081
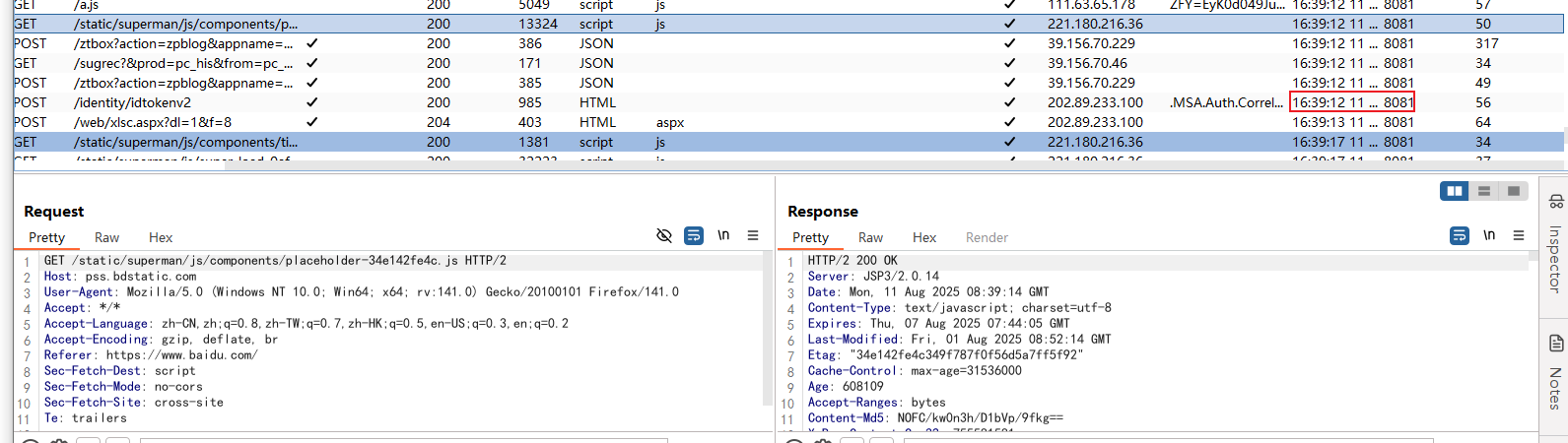
yakit
选择项目后,点击左上角的MITM,在右下面可以修改监听端口
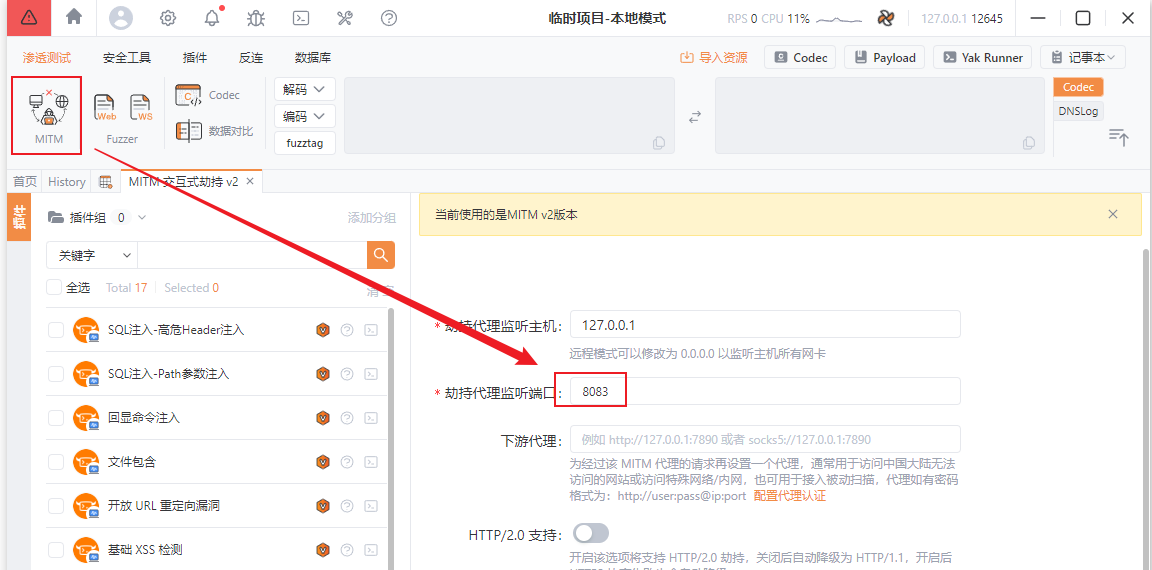
yakit抓包
尝试抓取手机应用程序数据包,尝试抓取微信小程序数据包
手机程序抓包方法一
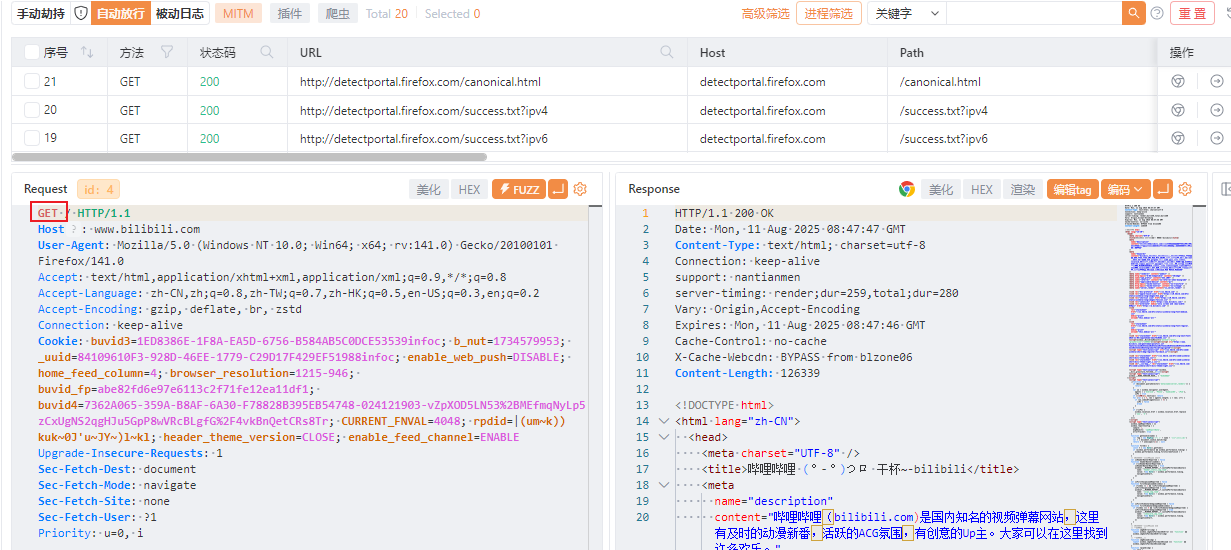
首先电脑打开移动热点
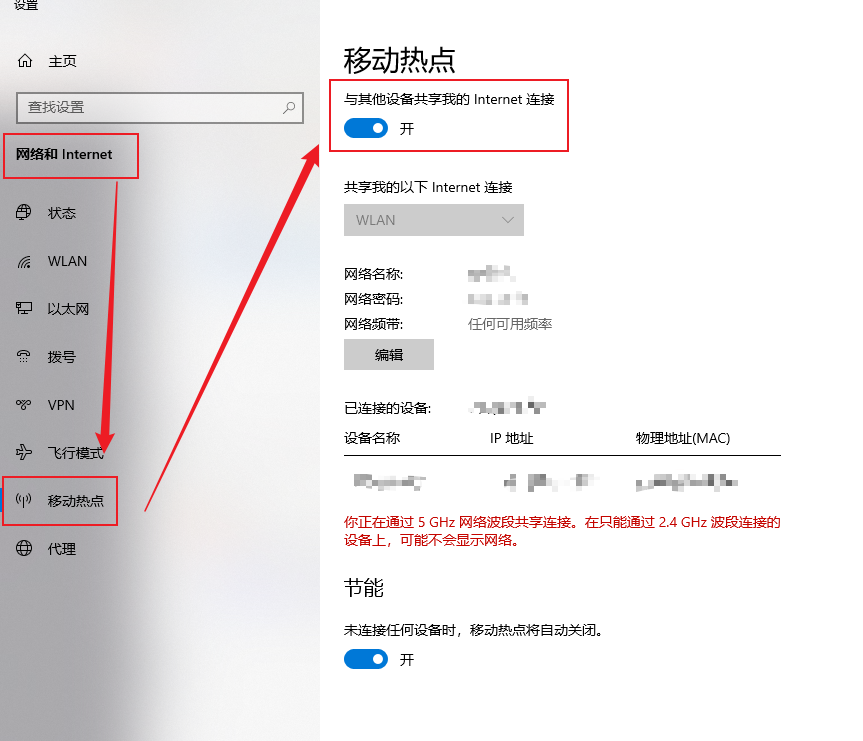
打开电脑cmd查看IP,找到无线局域网适配器,查看本机地址
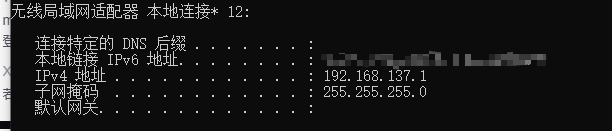
到burp上添加新的代理监听项
移动端连接电脑热点,然后在WLAN界面,长按刚刚连接的网络,选择修改网络,
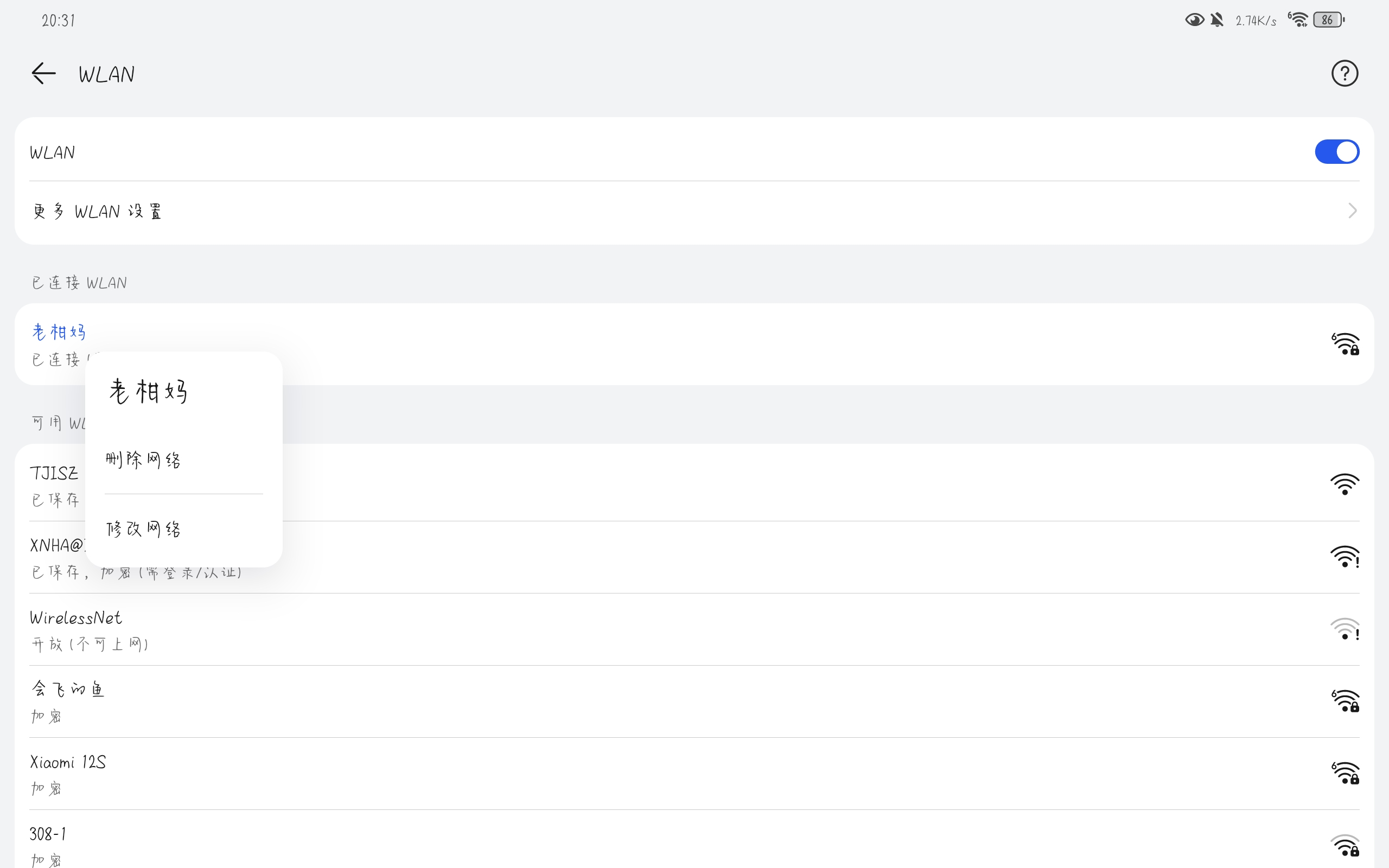
高级选项手动添加代理,代理主机名为电脑的IP,端口为burp监听的端口,保存即可
打开浏览器输入代理的主机IP和端口号,安装burp的证书

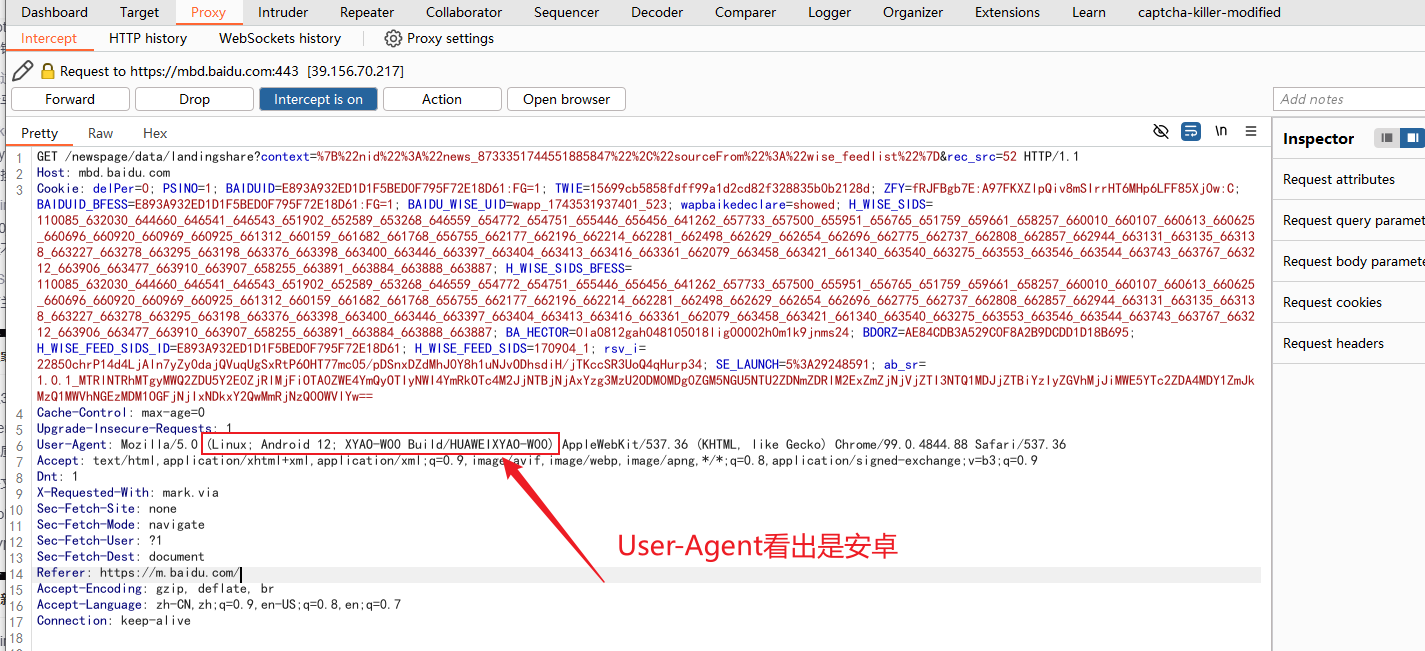
安装完证书后就能够开始访问网络了,这是后返回burp就能看到移动端访问外网的流量信息
方法二
手机与电脑连接同一个网络,开启手机网络代理,将数据包发送给电脑即可
预习html基础知识,思考浏览器如何区分html和js的,因为两者混写在一起
一、核心区分机制
1. HTML 解析模式(初始状态)
- 浏览器从字节流开始解析(网络传输的原始二进制数据)
- 遇到
<!DOCTYPE html>时:- 激活 标准模式(而非怪异模式)
- 但不直接影响代码类型识别,仅决定渲染规则
- 默认进入 HTML 词法分析状态,将内容视为 HTML
2. <script> 标签的触发作用
<!-- 示例 --> |
- 当解析器遇到
<script>开始标签:- 立即暂停 HTML 解析
- 切换至 JavaScript 解析模式
- 将后续内容交给 JavaScript 引擎(如 V8)
- 遇到
</script>结束标签:- 结束 JavaScript 解析
- 切回 HTML 解析模式
二、关键解析规则
1. 内容类型嗅探(Content Sniffing)
若未指定
Content-Type响应头:- 浏览器通过文件开头内容猜测类型(如
<!DOCTYPE html>暗示 HTML)
- 浏览器通过文件开头内容猜测类型(如
明确声明可避免歧义:
Content-Type: text/html; charset=utf-8 # 强制按HTML解析
2. 解析状态机(State Machine)
浏览器解析器维护状态变量决定当前处理内容类型:
| 状态 | 行为 |
|---|---|
DataState |
默认状态,解析 HTML 标签/文本 |
TagOpenState |
遇到 < 进入此状态 |
ScriptDataState |
遇到 <script> 后激活,将内容视为 JS |
RCDATAState |
处理 <textarea>/<title> 等特殊标签内容 |
3. 特殊字符的转义规则
在 HTML 中:
<script> |
在 JavaScript 中:
// 遇到 `</script>` 会错误地终止解析! |
解决方案:
<script> |
三、边缘场景处理
1. 内联事件处理器
<button onclick="alert('JS!')">Click</button> |
on*属性值按 JavaScript 解析- 解析流程:
- 识别
onclick属性名 - 提取
alert('JS!')字符串 - 动态编译为 JavaScript 函数
- 识别
2. <script> 的 type 属性
| 类型声明 | 解析行为 |
|---|---|
<script> |
默认按 JavaScript 解析 |
<script type="text/javascript"> |
显式声明 JavaScript |
<script type="module"> |
按 ES6 模块解析 |
<script type="text/html"> |
不执行,视为自定义模板 |
3. XSS 防御的异常情况
恶意代码尝试混淆:
<scr<script>ipt>alert(1)</script> <!-- 被拆解的标签 --> |
浏览器解析步骤:
- 首次
<scr→ 进入临时标签收集状态 - 遇到
<script>→ 中断收集,开始新标签 - 最终解析为两个无效标签,不会执行 JS